The Topological Transformer: Tauformer
delivering domain-memory and faster cheaper attention
TLDR; Tauformer is a class of GPT-like Transformers that redesigns self-attention around a topology-aware scalar signal (taumode) computed from a domain Graph Laplacian, so the model can (a) deliver domain structure directly into attention and (b) cut inference KV-cache roughly in half, while showing \(\sim20\%\) time-per-token improvements vs a nanoGPT baseline in the presented tests (c) draw a pathway for the use of higher-dimensional embeddings.
Here is the new paper as promised.
Intro
In the arrowspace line of work, the core claim has been: embeddings are not just geometrical spaces, because any embedding dataset hides a graph and a topology that can be surfaced with a Laplacian-based view.
Tauformer is the extension of that idea from retrieval into the attention kernel itself: instead of treating attention as purely geometric (dot products), it becomes manifold-aware by delivering the topology when computing distances between query, key and value in the self-attention mechanism.
What Tauformer changes
Tauformer keeps the familiar GPT pipeline (Q, K, V projections + causal masking + softmax) but swaps the inner-product scoring kernel for a distance built from a taumode scalar per token/head. Concretely, each per-head vector \((x \in \mathbb{R}^D\)\) is mapped to a bounded Rayleigh-quotient-derived scalar \((\lambda_\tau(x))\), and attention logits become a function of \((-|\lambda_q - \lambda_k|)\) rather than \((QK^\top)\).
That single change has two important consequences:
- Attention can be seeded by a domain manifold (the Laplacian), not just by local vector geometry.
- The model no longer needs to cache the full key vectors at decode time, because the “key side” of scoring is now a scalar stream.
- The model can handle larger prompt lengths, context windows and emebeddings dimensions.
Domain-memory inside attention
Tauformer’s “memory” is not a bigger context window; it is a persistent domain structure that the attention kernel can consult at every step. The paper frames the Graph Laplacian built from a domain embedding space (e.g., a distilled knowledge base / distilled knowledge graph represented as embeddings) as a persistent memory that stays constant while the model trains or generates. Different way of managing this memory can be designed, opening to a potential class of different Tauformers that use memory in different ways.
In practice, this connects naturally to the broader “AI Memory Layer” direction already discussed in earlier posts: making the data layer more explicit, auditable, and topology-aware rather than relying only on geometric similarity. While the speedups have solid ground, this part is still speculative and only more larger experiments can support the claim that seeding the attention like this could provide better interpretability and control of token generation.
Why it shines at scale (speed + VRAM)
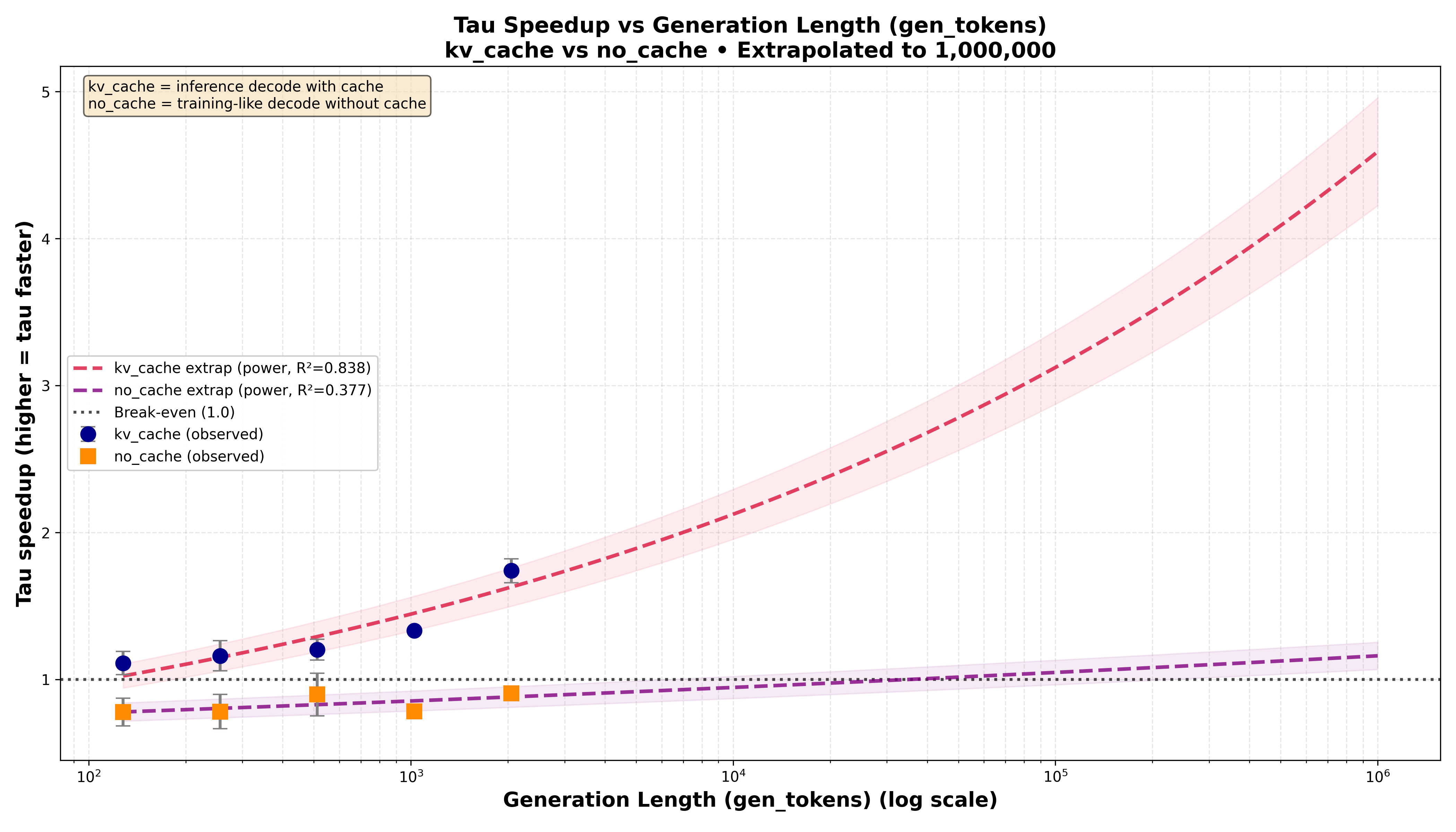
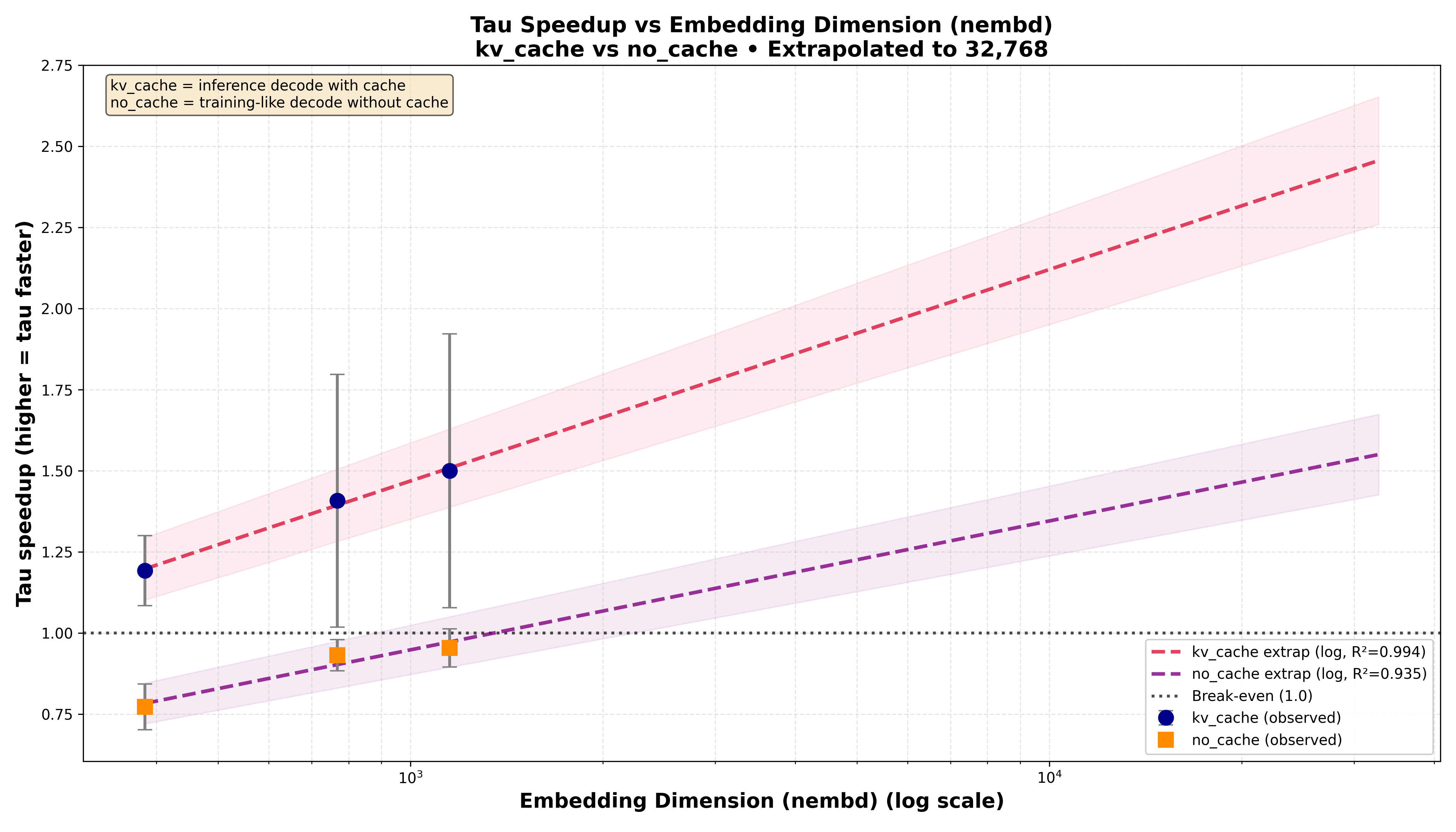
The immediate systems win is KV-cache: standard causal attention must store \(K\) and \(V\) (two full tensors), while Tauformer stores \(V\) plus the compact key-side scalar history \((\lambda_k)\), yielding roughly ~50% KV-cache size savings per layer (with small overhead for the scalar stream). Because decode-time memory grows linearly with context length \((T)\), this reduction translates into VRAM savings (in term of Gbytes per GPU) when prompts, context windows and vectors dimension get large.
On the compute side: the paper reports \(\sim20%\) time-per-token improvement vs a nanoGPT baseline in the provided benchmark setting, and motivates stronger advantages as context windows and embedding/head dimensions grow. A key part of the scaling story is sparsity: if the domain Laplacian is sparse, computing the \((\lambda_\tau\)\) signals can shift from a dense \((O(D^2))\) cost to a sparsity-dependent \((O(\mathrm{nnz}(L)))\), making the incremental overhead less sensitive to sequence length.
These diagrams show the speedups when context window, prompt length and emebeddings dimensions grow:
What’s next (and a note to sponsors)
Tauformer is a concept implementation (not a production claim), and the paper is explicit that very large-length regimes will likely need additional tricks (streaming/chunking/sparse attention over values, not only cheaper scoring). Still, the direction is clear: redesigning attention around topology-aware compression opens a pathway to larger context windows, higher-dimensional (including multimodal) internal representations, and potentially lower infra costs per generated token.
Enjoy the new year. This is tuned-org-uk — consider sponsoring on GitHub.
Keep challenging dimensionality
|

|